
뒤죽박죽 데이터분석 일기장
[Pandas] 판다스 기초 - 네이버 증권 일일 시세 크롤링 본문
안녕하세요. 이번 포스트에서는 네이버 증권 일일 시세 크롤링을 진행해 봤습니다.
저번 포스트에서는 특정 종목의 뉴스 기사를 크롤링 해왔는데 이번에는 일일시세를 크롤링을 해보겠습니다.
하지만, 저번에 기사를 크롤링 했을 때와는 조금 다른 방식으로 접근해야합니다.
저번에는 pandas 모듈을 import 했지만 이번에는 BeautifulSoup 과 requests 모듈도 import 해야합니다.
# 라이브러리 로드
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
우선, 미리 한 페이지 일일시세을 출력하는 함수는 적어보겠습니다.
# 종목 번호를 이용해 page에 따라 데이터를 읽어오는 함수
# """ 는 이 두개 사이의 행들은 주석 처리되며, 함수의 docstring 으로 사용됩니다.
def get_day_list(item_code, page_no):
"""
일자별 시세를 페이지별로 수집
1) URL 을 받아옴
2) request로 요청하기
(BS는 사용하지 않고 데이터프레임으로 만들기)
3) pd.read_html(response.text) 로 데이터프레임 만들기
4) 결측치 제거하기
5) 데이터 프레임 반환하기
"""
#1) URL 을 받아옴
url = f"https://finance.naver.com/item/sise_day.naver"
url = f"{url}?code={item_code}&page={page_no}"
#2) request 요청하기
headers ={"user-agent":"Mozilla/5.0"}
fina_link = requests.get(url, headers=headers)
#3) pd.read_html(response.text) 로 데이터프레임 만들기
temp = pd.read_html(fina_link.text)
#4) 결측치 제거하기
temp = temp[0].dropna()
#5) 데이터 프레임 반환하기
return temp
위 함수의 알고리즘을 살펴보자면
1. URL을 받는다.
2. Requests 요청해 HTTP을 URL로 보냅니다
3. 그러고 받아온 데이터를 텍스트 형태로 출력하고 BeautifulSoup을 이용해 수프 객체로 만들어서 추출하기 쉽게 만들어줍니다.
4. 결측치 제거하기
이렇게 해서 한 페이지에 속하는 일일시세 데이터를 출력할 수 있습니다.
위의 함수를 사용해서 카카오의 2번째 페이지 일일시세를 출력해 보겠습니다.
# 함수가 잘 만들어졌는지 확인하기
get_day_list("035720",2)결과:

그럼 한 페이지가 아닌 반복문을 사용해서 특정 날짜 이전까지의 시세를 출력해 보겠습니다.
저번에는 반복문 for을 사용했지만 이번에는 반복문 while을 사용해 출력해 보겠습니다.
import time
# web page 시작번호
page_no = 1
# 데이터를 저장할 빈 변수 선언
item_list = []
# while 문을 사용해 오늘 ~ 2021년 12월 01일까지 수집하기
while True:
# 한페이지를 수집하는 함수
df_price = get_day_list(item_code, page_no)
item_list.append(df_price)
# 마지막 행의 날짜 구하기
last_day = int(df_price.iloc[-1,0].replace('.',''))
# 날짜가 2021년 7월 1일 이전이라면 멈추기
print(page_no, last_day)
if last_day < 20220701:
break
page_no += 1
# 서버 부담 x
time.sleep(0.2)
len(item_list)
반복문 안의 알고리즘을 해석하자면
마지막 날짜는 날짜 데이터에서 replace 함수를 이용해서 "." 을 없애주고 8자리 숫자로 만들었습니다.
그리고 조건문을 활용해 특정 날짜보다 작을 시 break을 이용해 멈춰줍니다.
참고로 이런 반복된 동작들은 서버에 부담이 갈 수 있으니 time.sleep 함수를 이용해 잠깐식 멈춰줍니다.
이렇해서 특정 날짜 전까지의 일일시세를 출력할 수 있었습니다.
네이버를 예시로 들어보자면, 저는 함수 안에 7월 1일까지의 일일 시세를 출력하게 했습니다.
get_item_list("035420","NAVER")결과:
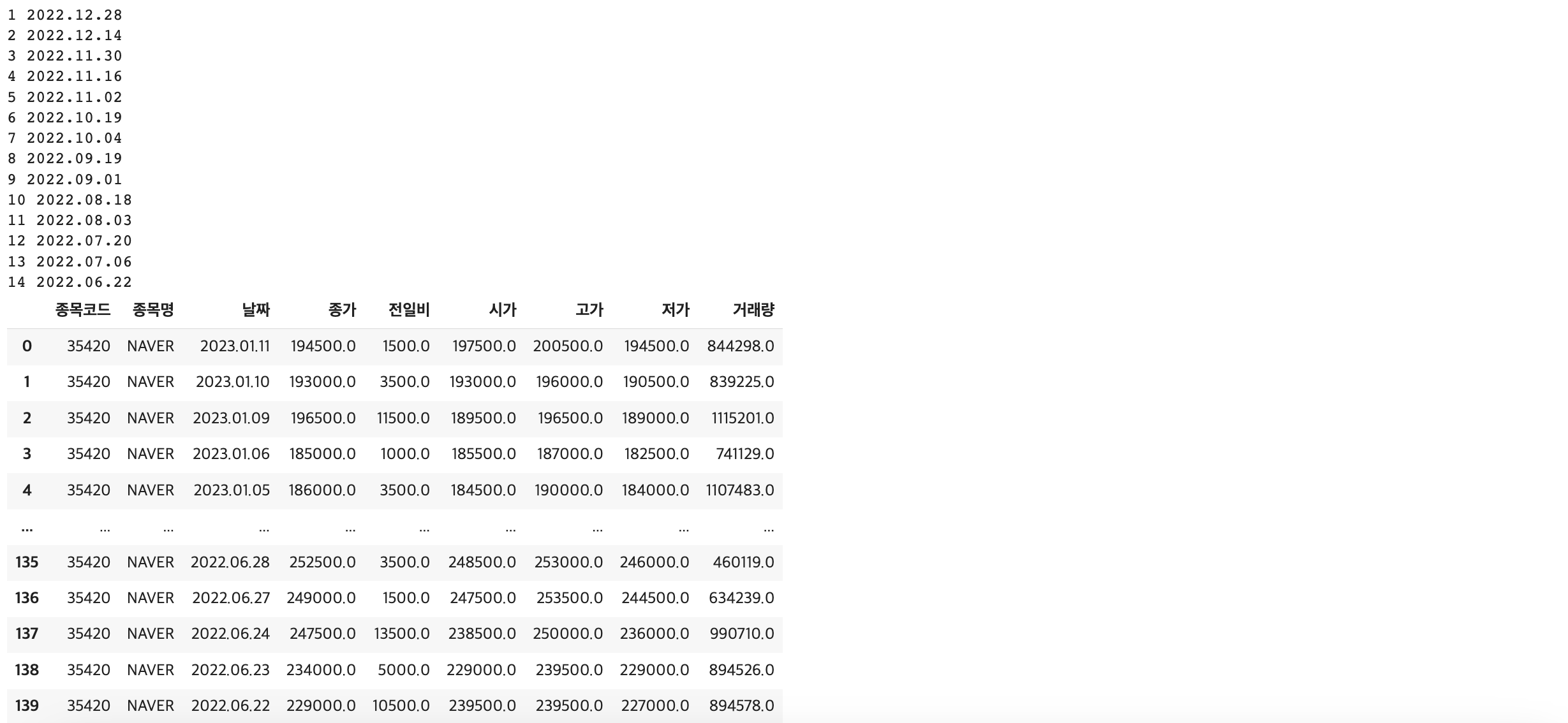
마지막에 6월 데이터가 보이는 이유는 break 하기 전에 이미 6월 데이터가 추가되었기 때문입니다.
지금까지 네이버 증권 크롤링 예제에 대해서 복습해 봤습니다. 혹시 틀린 부분이 있다면 댓글로 남겨주시면 감사하겠습니다. 지금까지 읽어주셔서 감사합니다.
'Pandas' 카테고리의 다른 글
| [Pandas] 판다스 기초 - 네이버 증권 기사 크롤링 (0) | 2023.01.14 |
|---|---|
| [Pandas] 판다스 기초 1 (0) | 2023.01.12 |

