
뒤죽박죽 데이터분석 일기장
[WIL] AI_School Week 6 EDA - 아파트 미분양 데이터 본문
안녕하세요. 오늘은 AI_School을 들은 6주차입니다. 이번 주에 배운 Exploratory Data Analysis(EDA) 내용을 복습해보겠습니다.
EDA는 데이터의 특징을 조사하는 데이터 분석 기법입니다. 이 기법을 통해 다양한 가설을 세울 수 있고, 이 가설을 통해 유용한 정보를 찾아낼 수 있습니다. 또한 EDA를 이용하면 데이터를 시각화할 수 있어 데이터를 보다 쉽게 이해할 수 있습니다.
이번에 분석할 데이터 셋은 아파트 미분양 데이터입니다. 저는 이 데이터로 진행한 탐색적 데이터 분석과 시각화를 검토하겠습니다. 이번 포스트에서는 구체적인 코드보다 EDA가 진행되는 흐름에 중점을 둬서 작성해 보도록 하겠습니다.
1. 라이브러리 불러오기
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# matplotlib 한글화 라이브러리
import koreanize_matplotlib
# 그래프에 retina display 적용
%config InlineBackend.figure_format = 'retina'→ EDA와 시각화에 필요한 라이브러리를 불러와줍니다.
2. 데이터 파일 불러오기
from glob import glob
file_names = glob("data/apt*.csv")
file_names = sorted(file_names)
file_names
df_first = pd.read_csv(file_names[0], encoding="euc-kr")→ glob 모듈을 사용해 직접 이름을 입력하지 않고 리스트 안에 넣어서 데이터를 저장합니다.
3. EDA
불러온 데이터를 어떤 식으로 전처리 하느냐에 따라서 추후 배울 모델링 진행시에도 많은 영향을 미친다고 합니다. 특히, 전체 프로젝트를 진행할 시에 EDA에 70~80프로의 시간을 투자한다고 하니 그 만큼 데이터 분석에서 EDA 단계는 중요한 단계입니다.
1. 데이터 미리보기
# 상위 5개의 데이터 보여주기
df.head()
# 하위 5개의 데이터 보여주기
df.tail()
# 랜덤으로 5개의 데이터 보여주기
df.sample()
# 데이터의 기본 정보, 데이터 타입, 메모리 사용량 확인
df.info()
2. 데이터 타입 변경
df_last["분양가격"] = pd.to_numeric(df_last["분양가격"], errors='coerce')→ 1번 과정으로 데이터를 요약할 시에 수치 계산이 필요한 데이터가 문자형으로 되어있으면 숫자형으로 변경해 줍니다.
3. 파생변수 생성
데이터 프레임 안에 있는 행 중에 분양가격은 제곱미터당 분양가격입니다. 하지만 평소에 부동산 기사를 보면 제곱미터당 분양가격이 아닌 평당 분양가격이라는 기준을 통상적으로 사용합니다. 따라서 이해하기 편하기 평당 분양가격이라는 파생변수를 생성해줍니다.
df_last["평당분양가격"] = round(df_last["분양가격"]*3.3,2)
df_last

미분양 데이터에서 규모구분이라는 컬럼에서는 미분양된 아파트의 규모를 규분해 놓았습니다. 하지만 모든 데이터가 너무 길고 중복되는 문자열이 너무 많습니다. 따라서 필요한 값만 남겨누고 나머지는 없애줍니다.
# 규모구분을 전용면적으로 변경하기
# regex(regular expression 정규표현식)
df_last["전용면적"] = df_last["규모구분"].str.replace("전용면적|제곱미터| |이하", "", regex=True)
df_last["전용면적"] = df_last["전용면적"].str.replace("초과", "~")
df_last
4. 불필요한 칼럼 제거하기
칼럼 중 분양가격과 규모구분을 필요하지 않습니다. 따라서 해당 행을 제거해줍니다.
# drop 사용시 axis에 유의 합니다.
# axis 0:행, 1:열
df_last = df_last.drop(columns=["규모구분", "분양가격"])
4. groupby & pivot_table로 원하는 데이터 집계하기
1. groupby를 사용해서 연도, 지역명별 평당 분양가격의 평균 구하기
# 연도, 지역명으로 평당분양가격의 평균을 구합니다.
df.groupby(["연도", "지역명"])["평당분양가격"].mean().unstack()
2. pivot_table을 사용해서 연도, 지역명별 평당 분양가격의 평균 구하기
pd.pivot_table(data=df, index="연도", columns="지역명",values="평당분양가격")
→ groupby나 pivot_table로 원하는 데이터 프레임을 출력할 수 있습니다. 하지만 groupby는 그룹화하는 일반적인 목적으로 데이터를 출력하는 반면에 pivot_table은 전문적으로 피봇테이블을 생성할 수 있습니다. 우선, groupby로 데이터 프레임을 출력해보고 그 다음에 피봇테이블로 생성하는 방법을 추천합니다.
5. 시각화
1. style.background_gradient()로 피봇테이블 내에서 히트맵 그리기
df.style.background_gradient()
2. 바 그래프 그리기
plt.figure(figsize=(12,4))
sns.barplot(data=df, x="연도", y="평당분양가격", ci=None).set_title("연도별 평당분양가격")
3. 선 그래프 그리기
# pointplot 으로 연도별 평당분양가격 그리기
plt.figure(figsize=(12,4))
sns.pointplot(data=df, x="연도", y="평당분양가격", color="green", ci=None).set_title("연도별 평당분양가격")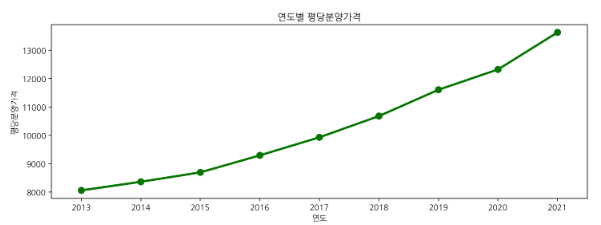
4. Box plot 그리기
# 연도별 평당분양가격 boxplot 그리기
plt.figure(figsize=(12,4))
sns.boxplot(data=df, x="연도", y="평당분양가격").set_title("연도별 평당분양가격")
5. Violin plot 그리기
# 연도별 평당분양가격 violinplot 그리기
plt.figure(figsize=(12,4))
sns.violinplot(data=df, x="연도", y="평당분양가격").set_title("연도별 평당분양가격")
6. Swarmplot 그리기
# 연도별 평당분양가격 swarmplot 그리기
import warnings
warnings.filterwarnings("ignore")
plt.figure(figsize=(12,4))
sns.swarmplot(data=df, x="연도", y="평당분양가격").set_title("연도별 평당분양가격");
간단하게 EDA를 진행해 보았습니다. 실전에서 EDA에서 진행할 때는 이것보다 더 많은 변수를 가지고 다양한 시각화를 표현하고 인사이트를 얻을 수 있습니다. 또한 각 시각화 함수의 공식 문서를 확인하면 그래프의 세부적인 사항들도 변경할 수 있습니다.
출처:
전국 신규 민간아파트 분양가격 동향 데이터 :
https://www.data.go.kr/data/15061057/fileData.do
주택도시보증공사_전국 신규 민간아파트 분양가격 동향_20211231
주택분양보증을 받아 분양한 전체 민간 신규아파트 분양가격 동향으로 지역별, 면적별 분양가격 등의 자료를 제공합니다.<br/>해당 데이터는 주택도시보증공사 홈페이지 및 통계청 KOSIS에서도
www.data.go.kr
유튜브 오늘코드 - https://www.youtube.com/todaycode
오늘코드todaycode
공공데이터 분석 데이터 시각화 캐글을 통한 머신러닝/딥러닝 튜토리얼 Pandas, Numpy, Scipy, scikit-learn, TensorFlow, Keras, Jupyter, Colaboratory 👉 페이스북 : https://www.fb.com/todaycode 👉 인스타그램 : https://
www.youtube.com