
뒤죽박죽 데이터분석 일기장
[Python] 네이버 데이터랩 API 사용기 및 월별 평균량 구하기 (1/2) 본문
안녕하세요. 이번 포스트에선 네이버 데이터랩에서 특정 키워드의 검색량을 네이버 API를 통해 추출해 보겠습니다.
네이버는 네이버 데이터랩이라는 서비스를 통해 특정 검색어의 검색량 정보를 제공합니다.
굳이 API가 없더라도 웹사이트에서 충분히 다양한 통계값을 얻을 수 있습니다.
하지만 월별 평균값은 주어지지 않기 때문에 일별 통계랑을 가져와서 월별 평균까지 내보는 것이 이번 포스트의 목표입니다.
※ 주의사항
네이버 데이터랩에서 제공되는 검색량 정보는 절대 수치가 아닙니다.
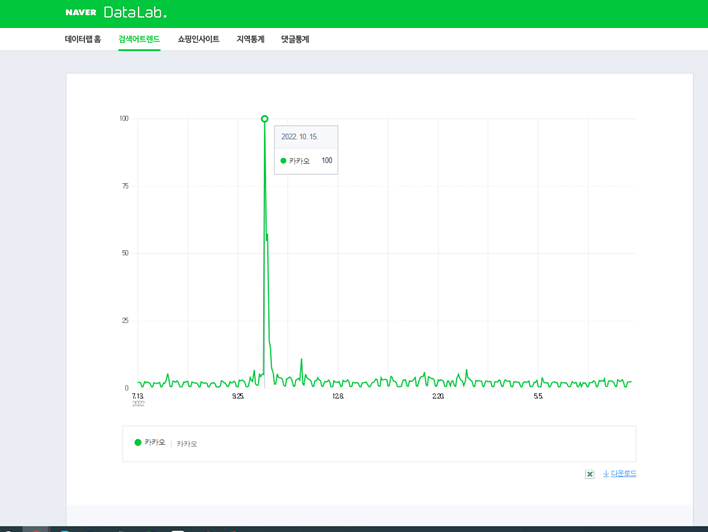
예를 들어 ‘카카오’라는 단어를 검색하게 된다면 설정한 날짜 중 카카오라는 검색어가 가장 많이 검색된던 날의 수치가
100으로 설정되고 이 값에 따라서 다른 값들이 비율로 조정됩니다. 따라서 이 수치들은 상대적입니다.
1. 네이버 데이터랩 API 키 값 생성하기
[해당링크] : https://developers.naver.com/products/service-api/datalab/datalab.md
데이터랩 - SERVICE-API
데이터랩 통합검색어 트렌드 통합검색어 트렌드는 네이버 통합검색에서 발생하는 검색어를 연령별, 성별, 기기별(PC, 모바일)로 세분화해서 조회할 수 있는 API입니다. 분석하고 싶은 주제군을
developers.naver.com

위 링크에 들어가 형광펜 쳐져있는 부분에서 사용 API를 데이터랩으로 설정하고 신청합니다.
신청 후 개인 키값이 생성되는데 이 키값이 있어야 API를 사용할 수 있습니다.
※ 주의사항
API 키값을 담고 있는 코드는 '절대로' 공유하시면 안됩니다. 추후에 금전적인 문제가 발생할 수 있으니 꼭! 인지 바랍니다.
2. 주피터 노트북으로 네이버 API 실행하기

[링크] : https://developers.naver.com/docs/serviceapi/datalab/search/search.md#python
통합 검색어 트렌드 - Datalab
통합 검색어 트렌드 통합 검색어 트렌드 개요 개요 통합 검색어 트렌드 API 개요 통합 검색어 트렌드 API는 네이버 데이터랩의 검색어 트렌드를 API로 실행할 수 있게하는 RESTful API입니다. 주제어
developers.naver.com
주피터 노트북에 작성한 코드는 네이버 개발자 Document에서 예시로 작성된 코드를 그대로 복사해 와서 진행했습니다. 복사된 코드에 발급받은 API 키 값을 입력하면 정상적으로 작동됩니다.
예시 코드를 보여드리겠습니다.
2-1. 라이브러리
# 네이버 데이터랩 API 실행을 위한 라이브러리
import os
import sys
import json
import urllib.request
# 월별 평균 및 산출을 위한 라이브러리
import pandas as pd
import matplotlib.pyplot as plt해당 API 실행을 위한 라이브러리를 불러옵니다.
2-2. API 키 변수 지정
client_id = "발급 받은 API ID를 입력하세요"
client_secret = "발급 받은 API Secret Key를 입력하세요"
url = "https://openapi.naver.com/v1/datalab/search";직접 발급 받은 API 키를 입력하면 됩니다.
2-3. 파라미터 입력
body = "{\"startDate\":\"2023-01-01\",\"endDate\":\"2023-06-30\",\"timeUnit\":\"date\",\"keywordGroups\":[{\"groupName\":\"수려한 효비담 발효 크림\",\"keywords\":[\"수려한 효비담 발효 크림\"]}]}";
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
request.add_header("Content-Type","application/json")
response = urllib.request.urlopen(request, data=body.encode("utf-8"))
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)네이버 API를 실행합니다. 원하는 정보를 파라미터에 입력해 body 변수에 입력하면 원하는 결과값을 얻을 수 있습니다.
저는 2023년 1월 1일부터 2023년 6월 30일까지 일별로 수려한 효비담 발효크림이라는 검색어의 검색량을 조사했습니다.


위 이미지는 네이터 데이터랩 공식문서에서 알려주는 파라미터값의 정의입니다. 참고하셔서 원하는 파라미터를 설정해 정보를 얻을 수 있습니다.
2-4. Json 변환
위 코드를 입력했을때 저는 이런 값을 변환받았습니다.

성공적으로 변환 받았으나 한 가지 문제점이 있는데요. 바로 string 형태로 반환이 되어서 dictionary로 작동하지 않습니다. 원하는 정보를 추출하기 위해선 dictionary 타입이어햐 합니다. 이때는 아래의 코드를 입력하면 쉽게 해결됩니다.
result = json.loads(result)
변환 후에는 데이터 프레임까지 성공적으로 생성할 수 있습니다.
df = pd.DataFrame(result['results'][0]['data'])
df.head()
이렇게 일별 검색량을 구할 수 있었는데요.
저의 최종 목표는 일별 검색량을 기반으로 월별 평균을 구하는 것이었지만 안타깝게도 검색량이 잡히지 않은 날짜는 출력되지 않습니다. 따라서 없는 날짜에 ratio 0값을 지정해 줘야 됩니다. 이 부분은 다음 포스트에서 이어서 설명하도록 하겠습니다.
'Python' 카테고리의 다른 글
| [Python] 네이버 데이터랩 API 사용기 및 월별 평균량 구하기 (2/2) (0) | 2023.07.18 |
|---|---|
| [Python] [5일차] 모듈과 패키지 (0) | 2023.01.07 |
| [Python] [5일차] 입출력, 파일 저장 및 출력 (0) | 2023.01.07 |
| [Python] [5일차] Class 파트 2 (2) | 2023.01.06 |
| [Python] [4일차] Class 파트 1 (0) | 2023.01.05 |


