
뒤죽박죽 데이터분석 일기장
[Python] [1일차] 변수선언, Data type 본문
오늘 포스트 내용은 멋쟁이 사자 AI School 8기 과정에서 본격적으로 강사님과 함께하는 수업을 복습하기 위해 정리하는 블로그 입니다.
서두로 강사님은 처음에 CPU, RAM, SSD(하드디스크)의 사용 의미를 컴퓨터 구조론을 통해 설명하시고 Python에 어떤식으로 적용하는
지 알려주셨습니다. 이와 관련된 내용은 이따가 다루도록 하겠습니다.
컴퓨터 언어는 크게 2가지 종류로 나눌 수 있습니다. 그리고 비교하자면 아래와 같습니다.
| Compiler (컴파일러 언어) | Interpreter (인터프리터 언어) |
| 1. 컴파일러는 전체 프로그램을 한 번에 실행합니다. | 1. 인터프리터는 한 번에 한 줄을 실행합니다. |
| 2. 따라서 속도가 빠릅니다. | 2. 따라서 속도가 느립니다. |
| 3. 컴파일러 생산 환경에 적합합니다. | 3. 인터프리터는 소프트웨어 개발 환경에 적합합니다. |
| 4. 컴파일러에는 C,C++,C#,Scala,Java 와 같은 언어를 사용합니다. | 4. 인터프리터는 Python, Javascript와 같은 언어를 사용합니다. |
*하지만 느린 인터프리터 언어는 데이터 분석 시에 Numpy로 생산성을 높일 수 있습니다.
현재 우리가 배우는 Python은 인터프리터 언어이며 위에 나와있는 인터프리터 언어의 특징을 이해해야 합니다.
강사님이 말씀하시길 코드를 잘 실행시키는 것도 중요하지만 오류 발생시 Debugging을 어떤 방향성을 잡고 하는지에 따라서 실력이 좌지우지 된다고 합니다.
따라서 "러버덕 디버깅"이라는 방법을 제시해 주셨습니다.
러버덕 디버깅
러버덕 디버깅이란?

문제나 오류가 발생해 진행할 수 없거나 막히는 상황이 왔을 때 가상의 존재를 만들어 지금까지 진행해 왔던 내용을 천천히 풀어나가며 설명하는 방법을 말합니다.
혼자 생각만으로 문제를 해결할 때는 보이지 않던 해결책이 누군가에게 설명하면서 그 해답을 찾게 된다는 것인데 이런 프로세스는 실제로도 큰 효과를 가진다고 합니다.
강사님은 코드에 오류가 발생하고 바로 동료나 주변 사람들에게 물어보기 보다는 우선 혼자 왜 그런 코드를 만들었는지 가상의 인물에게 설명하는 과정을 거치고 그래도 문제가 해결이 되지 않으면 물어보라고 조언해 주셨습니다.
1. 변수 선언
파이썬에서 가장 기본적인 문법인 변수선언에 대해서 알아보려고 하는데요.

위의 이미지는 가장 기본적인 변수 선언의 예시입니다. 해석하자면 x 라는 식별자 안에 데이터를 저장한 것입니다.
또한 이렇게 만든 변수를 RAM 저장공간을 만들어서 저장시킵니다.
여기서 식별자라는것은 저장공간을 구분해주는 문자열입니다.
파이썬에는 식별자를 작성시에도 몇 가지 룰이 있습니다. 크게는 2가지 룰로 나누어 보겠습니다.
1. 문법 : 어기만 안되는 룰 : 에러 발생
- 대소문자, 숫자, _만 사용가능
- 가장 앞에서 숫자 사용 불가능
- ex) data_1 (o) , 1_data (x)
- 멍령어(예약어) 사용 X
- def, if, for(x), print() 와 같이 파이썬에 내장되어 있는 명령어들을 사용할 수 없습니다
2. 컨벤션: 어겨도 실행은 되지만 보기에 좋지 않은 룰 : PEP8
- 변수 : jupyter_notebook : snake_case
- 하지만 보통 class 작성시에는 cakeHouse : camel case가 이용됩니다.
- 상수 : 대문자로 작성 : JUPYTER_NOTEBOOK
변수 지정 방법 - (식별자 1개, 데이터 1개), (식별자 n개, 데이터 n개), (식별자 n개, 데이터 1개)
# 식별자 1개, 데이터 1개
data1 = 1
# 식별자 n개, 데이터 n개
data2, data3 = 2, 3
# 식별자 n개, 데이터 1개
data4 = data5 = 4
그럼 지정된 변수에 대한 정보는 어떻게 확인할 수 있을까요?
주피터 보트북에서는 현재 Ram에 저장되어 있는 변수를 확인하기 위해서는
%whos
# 매직(스페셜) 커멘드 : %, %% 문법
# % : 커멘드 한줄 단위, %% : 셀 단위
# %ls, %reset, %%time, %%wirtefile ...
아래와 같은 값을 얻어 현재 저장된 변수를 확인할 수 있습니다. 추가적인 기능은 추후 포스트를 통해 정리하겠습니다.

변수 지정은 컴파일러 언어와 인터프리터 언어의 사이에서도 차이를 보입니다.
인터프리터 언어는 동적타이핑을 지원하는데 이는 변수 지정시 데이터 타입을 따로 지정하지 않아도 자동으로 데이터 타입이 지정되는 기능입니다.
하지만 컴파일러 언어의 경우
int data1 = -10와 같이 앞에서 어떤 데이터 타입인지 설명을 해줘야 합니다. 하지만 인터프리터 언어를 그럴 필요가 없습니다.
2. 데이터 타입
데이터 타입이라는 문법은 RAM을 효율적으로 사용하기 위해서 알아둬야할 문법입니다.
테이터 타입은 2가지로 분류할 수 있는데 기본 그리고 컬렉션 데이터 타입으로 구분할 수 있습니다.
1. 기본 데이터 타입
| int (정수형) | 2, -10, 50 |
| float (실수형) | 3.14, 2,5748920, -9.1342 |
| bool(논리형) | TRUE, FALSE |
| str(문자열) | "허니콤보", "파파존스", "KFC" |
2. 컬렉션 데이터 타입 - 식별자 1개, 데이터 n개
| list |
[]: 순서가 있고, 수정이 가능
|
| tuple |
() : 순서가 있고, 수정이 불가능
|
| dictionary |
{} : 순서가 없고, 수정이 가능, 순서값 > 키값
|
| set |
set() : 집합 데이터 표현 : 중복 데이터 허용 x : 교집합, 합집합, 차집합
|
* 컬렉션 데이터 타입에서 list 와 tuple은 순서가 있는 iterable() 데이터 타입입니다.
우리는 데이터 타입을 공부할 때 "CURD"를 기억해야 합니다.
C: Create
U: Update
R: Read
D: Delete
즉, 데이터 타입을 만들고, 수정하고, 원하는 값을 읽고, 삭제하는 것을 의미합니다.
그럼 우리는 Value의 타입을 어떤식으로 확인할까요?
바로 type() 함수로 확인 가능합니다.
#type()
data1, data2, data3, data4 = -10, 1.2, True, 'python'
type(data1), type(data2), type(data3), type(data4)
이제 위의 CURD를 이용해 컬렉션 데이터 타입을 알아보겠습니다.
2-1 List
List(리스트)는 순서가 있고 수정이 가능합니다.
그리고 리스트 생성시에는 대괄호를 이용해 지정합니다.
Create :
data1 = [1,2,3, 'A', 'B']
그럼 리스트 안에 있는 값은 어떤식으로 수정할까요?
Update :
data = [1,2,3,4,5, "A", "B"]
#A를 F로 바꿔준다
len(data)
#6번째, 인덱스로는 5를 입력해서 값을 바꿔준다.
data[5] = "F"
리스트 안에 있는 특정 값을 읽고 싶다면? Masking 이라고도 불린다.
Read :
data1 = [1, 2, 3, 'A', 'B']
print(data1)
# data[] : [idx], [key], [start : end], [start:end:stride]
# start에 데이터 x : 가장 앞, end에 데이터 x : 가장 뒤
#2번째 값
data1[3]
#2번째부터 3번째 값
data1[2:4]
#3번째부터 마지막까지 값
data1[3:]
#처음부터 1번째까지 값
data1[:2]
#처음부터 마지막까지 한 칸 띄고 출력한 값
data1[::2]
음수로 masking 하는 경우?
data1 = [1, 2, 3, 'A', 'B']
print(data1)
#뒤에서 2번째
data1[-2]
#뒤에서 2번째에서 마지막까지
data1[-2:]
#모든 수 출력, but 뒤에서 하나씩
data1[::-1]
Delete:
# list에서 데이터 삭제
data1 = [1, 2, 3, 'C', 'B']
print(data1)
print(data1[2:4])
# 2~3번째 삭제
del data1[2:4]
print(data1)
2-2 Tuple
Tuple(튜플)은 순서가 있고 수정이 불가능합니다.
Create:
data2 = (1, 2, 3, 'A', 'B')
튜플에서 수정하려고 하면
Update X :
print(data2)
data2[3] = 'C'
print(data2)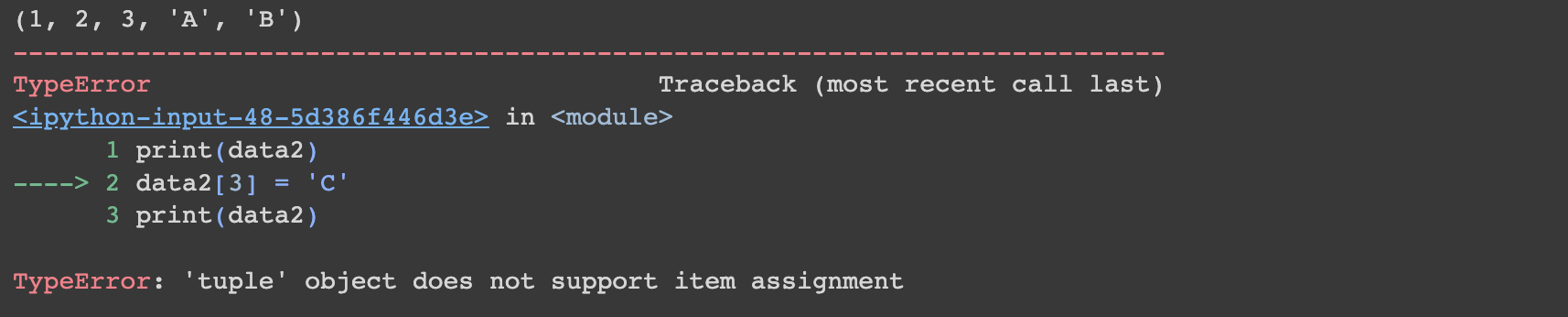
에러가 뜨면서 튜플은 수정이 불가하다는 문구가 나옵니다.
그럼에도 불구하고 우리가 튜플을 사용하는 이유는 뭘까요?
바로 튜플은 리스트보다 저장공간을 적게 사용합니다.
import sys
d1, d2 = [1, 2, 3], (1, 2, 3)
sys.getsizeof(d1), sys.getsizeof(d2)
sys.getsizeof() 함수를 통해서 확인할 수 있었습니다.
2-3 Dictionary
Dictionary은 순서가 없고, 수정이 가능합니다. 그리고 Key 와 Value를 한 쌍을 이루어 데이터를 저장합니다.
Create :
#dictionary는 중괄호 {} 를 이용해 변수 지정합니다.
data3 = {'one' :1 , 2: "two"}
Update :
data3 = {'one' :1 , 2: "two"}
print(data3)
data3["one"] = 10
print(data3)
Read :
data3 = {'one' :1 , 2: "two"}
data3["one"]
Delete :
# 데이터 삭제 : delete : del 데이터선택
# dictionary에서 데이터 삭제
print(data3)
del data3[2]
print(data3)
2-4 Set
Set은 집합 데이터의 표현이고 중복 데이터가 허용되지 않습니다.
data4 = set([1,2,3,2]) #<- 중복 x
data4, type(data4)
그럼 Set를 사용하는 이유는 뭘까요? 바로 교집합, 합집합, 차집합과 같은 기능을 이용할 수 있기 때문입니다.
d1, d2 = set([1, 2, 3]), set([2, 3, 4])
#교집합 : &, 합집합 : |, 차집합 : -
print(d1 & d2, d1 | d2, d1 - d2)
'Python' 카테고리의 다른 글
| [Python] [2일차] 데이터 Skill 비교, 연산자 (0) | 2023.01.03 |
|---|---|
| [Python] [1일차] 얕은복사, 깊은복사, 문자열 데이터 활용 (0) | 2023.01.02 |
| [Python] 조건문 응용 (0) | 2022.12.23 |
| [Python] 조건문, 반복문 (0) | 2022.12.23 |
| [Python] List, Dictionary (0) | 2022.12.23 |


